Aggregation
A type can have attributes (properties), but attributes have a type of their own (for example the type “name”) and must be part of a composite type: thus an attribute defines a connection or aggregation of two types. For example, “name” can be an attribute of the type “employee”. Using the semantic language, this attribute can be specified as “employee its name”. Each composite type has some positive number of attributes, but a base type such as “name” does not have any attribute. Within a data model, a type can be identified by a name. At the same time a collection of properties (attributes) identifies a composite type: there may not be two types with the same collection of attributes. Moreover, within a data model a composite type has only one definition: the principle of convertibility. Convertibility not only applies to the conceptual level (the data model), but also applies to instances of composite types. Using the following simplified definition of the type “employee”, the two mentioned instances of “employee” may not be registered in a same database:
type employee = name, address, town, department.
| employee | name | address | town | department |
|---|---|---|---|---|
| 123 | John | 43 Q Street | Greenfield | 12 |
| 432 | John | 43 Q Street | Greenfield | 12 |
These two instances are conflicting with the principle of convertibility, but are allowed by an equivalent relational model because relational modeling only requires uniqueness of a primary key value. However, readers might not agree, because a father and his son can have the same shown properties. If we want to deal with such possible situations then it is necessary to extend the definition “employee” with properties such as “birth_date” and “function” or “salary” enabling us to make a distinction between the two instances.
Types are described by their permanent properties, in particular the properties relevant for the information needs at hand. If a property or attribute is not relevant to all instances of a certain composite type then the data definition must be improved. The definition of object types related to a same real life object as “person” needs not be the same for all organizations; the FBI and CIA have more information needs than a local administration department.
Role attributes
Attributes of a same composite type may be based on the same base type. In that case both attributes are based on the aggregation of the same two types. In order to be able to distinguish these properties we must add different roles (prefixes). For example, a type as “project” can have a starting date and a final date:
type project = starting_date, final_date, budget, managing_employee.
Here “project its starting_date” and “project its final_date” are examples of role attributes.
Since each composite type is defined by its attributes and each attribute has its own (base)type, the types of these attributes must be predefined before the composite type can be specified: each composite type thus refers via its attributes to already existing types. This is the principle of relatability, which leads to hierarchical data structures. An important consequence of relatability is that mutually dependent types as in the following example may NOT be defined:
type employee = name, address, town, birth_date, department. type department = location, manager_employee.
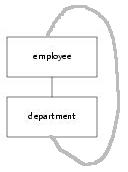
If we want to design a correct data model for employee and department data, a possible solution is to delete the attribute “department its manager_employee” and to introduce the attribute “employee its function”, which is based on a base type “function”. Now an employee can have a function such as “manager”. A consequence of this improved model, however, is that it allows for many managers per department. Later on (see static restrictions) we shall discuss how to restrict (a part of the data definition) the number of managers per department.
Improved data model:type employee = name, address, town, birth_date, function, department. type department = location.

Contrary to indirect recursion in a data model, direct recursion is not conflicting with relatability because it does lead to mutual dependent data definitions. An example is that each employee has a supervisor:
type employee = name, address, town, birth_date, function, department, supervising_employee.
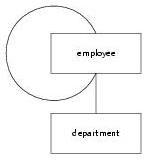
Another example of a directly recursive data model:
type person = birth_date, mother_person, father_person.
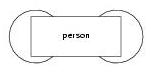
The graphical notation of a data model is clearly depicting the dependency between the definition of different composite types: a graphical reference starts in the bottom line of a type rectangular and ends in the top line of that rectangular. For reasons of understandability, abstraction hierarchies do not show the involved base types.
Contrary to the Entity-Relationship approach where “vertical” structure is defined through entities, relationships and cardinalities, the semantic approach does not need to use cardinalities: the entity with the “n”-cardinality is placed above the entity having the “1”-cardinality if there is no recursion. Relationships are defined inherently through attributes. This allows us to make a clear distinction between the data belonging to organizations with different ways of organizing labor.
The data model above applies to an organization where each employee is only working for one department and the following data model applies to an organization where employees may work a different number of hours per week for different departments in different functions:
type employee = name, address, birth_date, town. type department = location. type work = employee, department, function, hours.
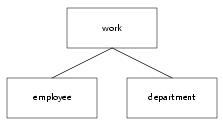
Using the Entity-Relationship-approach both situations are graphically modeled almost similarly, only the cardinalities are differing:
Employees only working for one department:

In terms of an informal relational model (primary keys marked bold; foreign keys marked italic):
employee (emp#, name, address, town, birth_date, dept#, function); department (dept#, location);
It is also possible that employees are working for more than one department:

The last model in terms of a relational model:
employee (emp#, name, address, town, birth_date); department (dept#, location); work (emp#, dept#, hours, function);
Because both the semantic model (using inherent references) and the relational model (using explicit sub set constraints on keys) define relationships through attributes it is easier to translate a semantic model into a relational model than to translate an ER-model into a relational model. A 1:n ER-relationship must be translated into a foreign key and in the case of an n:m relationship, the ER-relationship must be translated into a relation such as “work” in the last model. For further information on model transformation: Xplain2SQL
The semantic definition of types by a collection of attributes implies that types not mentioned left of the “=” symbol are base types. This also implies inherent specification of references or inherent relatibility. For example, the attribute “employee its department” is referring to the type “department”. Consequently, we do not need not to specify any explicit sub-set constraint as in the CREATE TABLE command used by the relational language SQL. See for example the following formal SQL2 definition of the relations “department” and “employee”:
CREATE TABLE department ( dept# INT NOT NULL, location VARCHAR (12), PRIMARY KEY (dept#));
CREATE TABLE employee ( emp# INT NOT NULL, name VARCHAR (30), address VARCHAR (15), town VARCHAR (22), birthdate DATE, function VARCHAR (9), dept# INT NOT NULL, PRIMARY KEY (emp#), FOREIGN KEY (dept#) REFERENCES department (dept#));
Primary keys may never have the value NULL, but for foreign keys, the NOT NULL rule is not mandatory!
The semantic Xplain-DBMS derives the required sub-set contraints from the data model itself. A sub set constraint means that only existing objects may be referred to and that a referenced object may not be deleted. The Xplain-DBMS also offers an interactive way to define data models using a dialogue, which is easier for naive users.
An extended definition of the data model for an organization where employees are only working for one department could be (including value domains):
base location (A12). type department (I4) = location. base name (A30). base address (A15). base town (A22). base date (D). base function (A9). base salary (R6,2) (0..*). type employee (I5) = name, address, town, birth_date, function, department, salary.
Contrary to the semantic and the relational model, the Entity-Relationship model is not supplied with a data manipulation language.
See next Generalization or Classification